이번에는 t분포에 대해 정리하려고 한다.
t분포는 연속확률분포의 하나로써, 정규분포인 모집단의 평균을 추정해야 하지만 표본의 크기가 작고 모집단의 분산을 알 수 없는 경우에 이용된다고 한다.
t분포는 Student's t-distribution이라고 불리기도 하는데, 그 이유는 처음 t분포를 발견한 William Sealy Gosset이 논문을 발표할 때 Student라는 가명을 사용했기 때문이다. 왜 그랬냐하면 그가 다니던 맥주회사 기네스에서 그가 본명으로 발표하는 것을 원치 않았는데, 자신들이 t분포를 사용한다는 것을 경쟁사한테 알리고 싶지 않았던 것이다.
1. 정의
$Z$는 표준정규분표 $\mathcal{N}(0, 1)$를 따르는 확률변수, $Q$는 자유도 $k$인 카이제곱분포를 따르는 확률변수이고 둘이 독립일 때, 다음과 같이 정의되는 확률변수 $T$는 자유도가 $k$인 t분포를 따른다. 왜 이렇게 정의되었는지는 차차 생각해보기로 하자.
$$ T = \frac{Z}{\sqrt{\frac{Q}{k}}} \Rightarrow T \sim t_k$$
그리고 이 확률변수는 아래와 같은 확률밀도함수를 갖는다.
$$ f(t) = \frac{\Gamma[\frac{(k+1)}{2}]}{\sqrt{\pi k} \Gamma(\frac{k}{2})}\cdot\frac{1}{[\frac{t^2}{k} + 1]^{\frac{(k+1)}{2}}}, \quad -\infty < t < \infty $$
증명은 가볍게 넘어가고(^^), 확률밀도함수의 그래프가 어떻게 생겼는지 보자.
2. 그래프
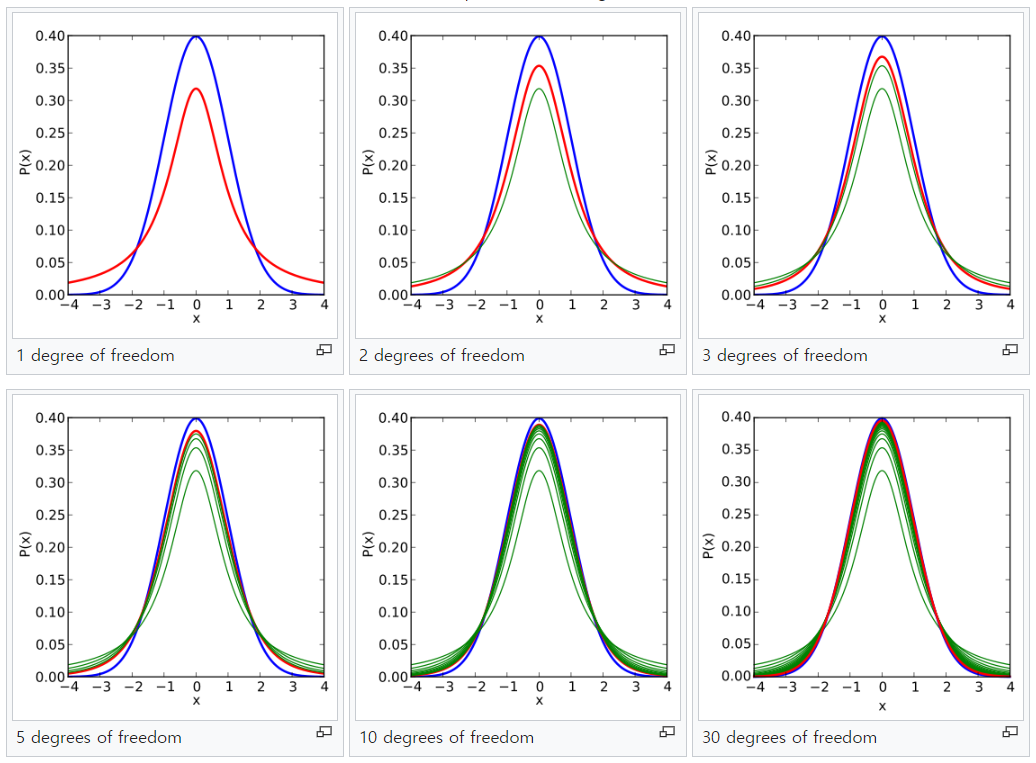
왼쪽 위의 그림부터 보면, 파란색이 정규분포곡선($\mathcal{N}(0, 1)$)을 나타낸 것이고 빨간색이 자유도가 1인 t분포의 곡선을 나타낸 것이다. 두 곡선의 모양을 비교해보면 t분포는 정규본포와 비슷하게 종 모양이지만 양쪽 꼬리가 더 두껍고, 봉우리는 더 낮은 것을 볼 수 있다. 그리고 자유도가 커질수록 점점 정규분포와 가까워지며 자유도가 30(맨 오른쪽 아래)인 그림을 보면 거의 똑같아지는 것을 볼 수 있다. 그래서 여기서 자유도를 nomality parameter라고 부르기도 한다. 사실 이 부분에서 자유도가 커지면 왜 정규분포와 가까워지는지, 이게 t분포의 본질과 어떤 관련이 있는지 더 탐구해보고 싶지만.. 요즘 시간이 없어서 타협모드이므로.. 아쉽지만 넘어가기로 한다.
3. 표본분산과의 관계
처음에 t분포를 모집단이 정규분포이고, 모평균을 추정하고 싶은데 모분산을 알 수 없고 표본의 크기가 작은 경우에 활용할 수 있다고 했다. 상황을 한 번 상상해보자.
- 어떤 모집단이 있고, 이 모집단은 정규분포를 따르는 것 같다.
- 이 모집단의 모평균을 추정하고 싶은데, 모분산을 몰라서 Z 통계량을 이용한 통계적 추정 방법을 없다.
- 게다가 표본의 크기 $n$이 30보다 작아서 중심극한정리에 의해 표본평균의 분포가 정규분포라고 할 수도 없을 것 같다.
이 상황에서 어쨌든 우리는 표본을 뽑을 수 있고, 보통은 중심극한정리와 Z 통계량을 이용해서 추정을 하였지만, 이번에는 그럴 수 없는 상황이다. 그러면 우리가 알고 있는 것은 뭔가? 우리는 표본분산 $s^2$은 알 수가 있다. 따라서 Z통계량을 아래와 같이 수정해보자.
$$ \frac{\bar{X} - \mu}{\frac{\sigma}{\sqrt{n}}} \Rightarrow \frac{\bar{X} - \mu}{\frac{s}{\sqrt{n}}} $$
단순히 모분산을 알 수가 없으니 표본분산을 이용해서 통계량을 바꿔본 것이다. 그런데 이 바뀐 통계량을 $\sigma$로 나누어주면 다음과 같은 것을 발견할 수 있다.
$$ \frac{\frac{\bar{X} - \mu}{\sigma}}{\frac{s}{\sqrt{n}\sigma}} = \frac{\frac{\bar{X} - \mu}{\frac{\sigma}{\sqrt{n}}}}{\sqrt{\frac{s^2}{\sigma^2}}}$$
$$ \Rightarrow \frac{\bar{X} - \mu}{\frac{\sigma}{\sqrt{n}}} \sim \mathcal{N}(0, 1), \quad \frac{s^2}{\sigma^2} \sim \frac{\chi_{n-1}^2}{n-1}$$
즉, 처음에 정의한 t분포를 따르는 확률변수의 모양 $T = \frac{Z}{\sqrt{\frac{Q}{k}}}$와 같은 형태이므로, 통계량 $\frac{\bar{X} - \mu}{\frac{s}{\sqrt{n}}}$는 자유도가 $n-1$인 t분포를 따른다. 이 통계량을 t통계량이라고 하는데, 우리는 이것을 가지고 위와 같은 상황에서 통계적 추정이나 가설검정을 해 볼 수가 있게 된다.
'Study > 통계' 카테고리의 다른 글
| 불편추정량(Unbiased Estimate) - 표본분산은 왜 n-1로 나누나? (3) | 2020.03.19 |
|---|---|
| 카이제곱분포(Chi-squared distribution) (0) | 2020.03.19 |
| 통계적 추론 - 가설검정(Hypothesis test) - 2 (0) | 2020.03.12 |
| 통계적 추론 - 가설검정(Hypothesis Test) - 1 (0) | 2020.03.10 |
| 통계적 추론 - 통계적 추정(Statistical Estimation) (0) | 2020.03.05 |


