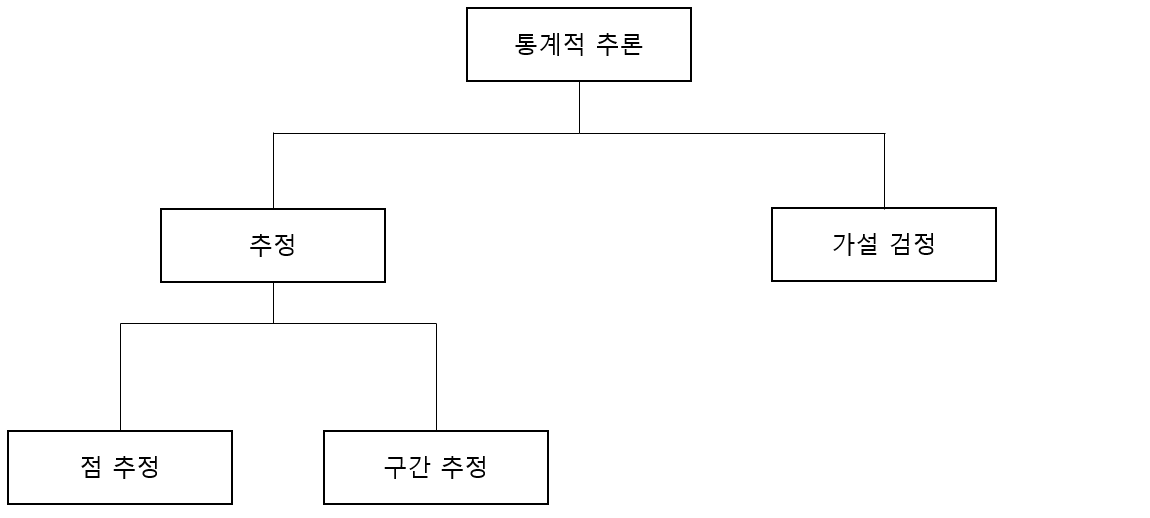
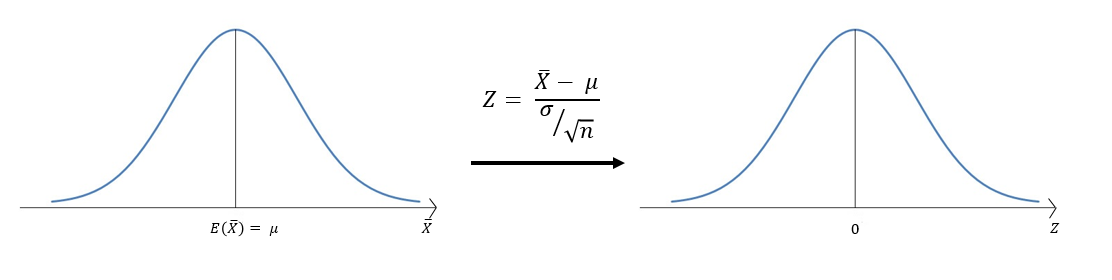이번엔 가설 검정에 대해 정리하려고 한다.
정리하려고 여러 자료를 찾아보던 중 엄청나게 설명을 잘 해놓은 유튜브 영상이 있어, 이 영상에 나온 내용 위주로 정리하려고 한다. 정말이지 너무 설명을 깔끔하게 잘 해놔서 존경스럽다. 나도 이렇게 명확하고 깔끔하게 잘 설명할 수 있으면 좋으련만. 영상 주소는 여기. 나처럼 통계를 공부해보려는 사람에게 아주 유용한 강의가 채널에 잔뜩 올라와있다. 강추!!
그럼 가설 검정에 대한 이야기를 시작해보자.
가설 검정이란, 말그대로 어떤 '가설'이 있을 때, 그 가설이 맞는지 틀린지 통계적인 관점에서 '검정'해보는 것이다.
먼저 어떤 상황에서 가설 검정을 하게 되는지를 보면 좀 더 순조롭게 이해가 된다.
상황 X)
어떤 분포를 알 수 없는 모집단이 있을 때, 어떤 사람 A가 와서 이 모집단의 평균값이 $\mu'$라고 밑도 끝도 없는 주장을 해대고 있다. 나는 대충 어림잡아 봐도 $\mu'$은 아닐 것 같아 상당의 의심이 드는데, 이 사람이 사기꾼인지 아닌지 알아보기 위해 통계적인 방법으로 A의 '가설'을 검증해보려고 한다.
여기서 A의 주장을 즉 가설을 '귀무가설(Null hypothesis)'이라고 한다.
그 이름도 어려운 귀무가설은 돌아갈 귀, 없을 무를 써서 무無로 돌아갈 가설을 의미한다. 즉, 터무니 없는 가설이므로 기각될 가설이라는 뜻이다. 기호로는 보통 $\mathcal{H_{0}}$로 표현한다.
아무리 터무니없어 보여도 귀무가설이 참이 확률이 있다. 따라서 귀무가설은 기각될 수도 있고 채택될 수도 있다. 쉽게 말해 통계적으로 검정을 해보았을 때 기각된다 함은 '옳지 않은 가능성이 높다고 판단'한다는 것이고 채택된다는 것은 '옳을 가능성이 높은 것으로 판단'한다는 것이다.
귀무가설이 기각될 때 채택하는 가설로 '대립가설(Alternative hypothesis)'이라는 것이 있다. 이름 alternative에서 알 수 있듯이 단순히 귀무가설이 기각되면 채택하는 가설이다. 기호로는 보통 $\mathcal{H_{1}}$로 표현한다.
예를 들어 귀무가설이 '이 모집단의 평균이 100입니다!'라고 했을 때 대립가설은 '이 모집단의 평균은 100이 아니다.' 또는 '이 모집단의 평균은 100보다 크다.' 따위가 될 수 있다.
그렇다면 위의 상황 X에서 귀무가설과 대립가설을 정의해보면 어떻게 될까? 아래처럼 될 것이다.
귀무가설 $\mathcal{H_{0}}$: 모집단의 평균값이 $\mu'$이다.
대립가설 $\mathcal{H_{1}}$: 모집단의 평균값이 $\mu'$가 아니다.
자 그러면 어떤 방식으로 통계적 가설 검정을 하는 것일까?
먼저 이전 글에서 다룬 중심극한정리와 통계적 추정에 대한 내용이 숙지되어 있어야 한다.
A라는 사람이 모집단의 평균이 $\mu'$라고 주장하고 있다. 가장 좋은 방법은 이 모집단을 전수조사해서 평균을 내보는 것이지만 모집단이 너무 커서 시간적으로나 비용적으로나 불가능하다. 이런 상황에서는 통계적 추정에서 그랬던 것처럼 표본을 뽑아서 추론해보는 수밖에 없다.
그러니까 이사람 말대로라면 모집단의 평균이 $\mu'$라는 거니까, 중심극한정리에 의하면 표본평균의 평균 역시도 $\mu'$이어야 한다. 즉, 수학적으로 이 상황의 귀무가설과 대립가설을 수학적으로 표현해보면 아래와 같다.
귀무가설 $\mathcal{H_{0}}: E(\bar{X}) = \mu'$
대립가설 $\mathcal{H_{1}}: E(\bar{X}) \ne\mu'$
그럼 이제 표본을 뽑아보자.
아래 그림처럼 모집단에서 랜덤 샘플링한 표본의 평균을 $\bar{X_{1}}$, 분산을 $s^2$이라고 하자. 여기서는 모집단의 분산 $\sigma^2$이 알려져 있다고 가정하겠다.

중심극한정리에 의하면, 표본의 크기가 충분히 클 때(30 이상일 때) 표본평균의 분포는 다음과 같은 정규분포를 따른다고 했다. $$\bar{X}\sim\mathcal{N}(\mu, \frac{\sigma^2}{\sqrt{n}})$$
그러니까 지금처럼 표본을 하나 뽑는 행위는 아래 그림처럼 정규분포에서 표본평균을 하나 뽑는 것과 같다고 지난 글에서도 이야기했었다.

다시 말해, 만약 A의 가설이 옳아 모집단의 평균이 $\mu'$가 맞다면 $\mu'$를 평균으로 하는 정규분포에서 샘플링을 하는 것이기 때문에, 높은 확률로 $\mu'$근처의 표본 평균이 샘플링될 것이고, 낮은 확률로 양 끝에 있는 표본평균이 샘플링될 것이다.
따라서 만약 추출한 표본의 평균 $\bar{X_{1}}$가 위 그림처럼 오른쪽 끝에 있는 놈이라면, 그 상황은 다음 두 가지로 생각해볼 수 있다.
1) A의 가설이 옳고, 낮은 확률로 $\bar{X_{1}}$가 뽑힌 것이다.
2) $\bar{X_{1}}$가 뽑힐 확률이 너무 낮으니까, A의 가설이 틀렸다고 봐야 한다. 즉, 저런 정규분포가 아닐 것이다.
'낮은 확률'의 기준을 정하는 것은 사용자의 몫이다. A의 가설이 옳다고 했을 때 $\bar{X_{1}}$가 뽑힐 확률이 1% 미만이면 A의 가설이 틀렸다고 할 수도 있고 1%가 아니라 5%, 10% 정하기 나름이다. 보통은 5%를 많이 쓰는 것 같다. 이 때의 '낮은 확률'을 '유의 수준 $\alpha$(Significant level)'라고 하며 이것을 5%로 정했다고 했을 때 $\alpha = 0.05$가 된다. 5% 미만의 확률로 뽑히는 영역 즉 $\alpha = 0.05$인 부분이 아래 그림과 같다고 했을 때, 저 영역을 $\alpha=0.05$에 해당하는 '기각역'이라고 한다. 저기서 표본평균이 뽑힌다면 귀무가설이 틀렸다고 기각할거니깐.
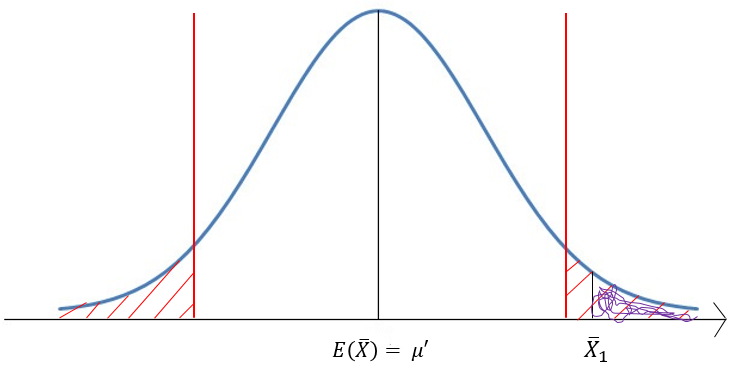
우리가 뽑은 표본의 평균 $\bar{X}$가 기각역 안에 있다고 해보자. 즉 사용자가 기각하기로 한 유의수준보다 낮은 확률로 뽑히는 곳에 있다(보라색 영역). 이 영역의 확률을 '유의 확률(Significant probability)' 또는 'p-value'라고 한다. 만약 보라색 영역의 확률이 2%라면 p-value=0.02가 된다.
p-value를 이용해서 귀무가설이 기각될 조건을 다시 한 번 써보면 p-value < $\frac{\alpha}{2}$라고 할 수 있다(2로 나눠주는 이유는 기각역이 양쪽 끝에 있으므로).
위 정규분포에서 p-value 즉 $\bar{X_{1}}$가 뽑힐 확률을 계산하는 것은 간단하다. 표준화를 해서 표준정규분포표를 이용하면 된다. 참고로 이런 식으로 표본 하나와 표준정규분포를 이용해 검정하는 방법을 '1표본 Z검정'이라고 한다고 한다.
'Study > 통계' 카테고리의 다른 글
| 불편추정량(Unbiased Estimate) - 표본분산은 왜 n-1로 나누나? (3) | 2020.03.19 |
|---|---|
| 카이제곱분포(Chi-squared distribution) (0) | 2020.03.19 |
| 통계적 추론 - 가설검정(Hypothesis test) - 2 (0) | 2020.03.12 |
| 통계적 추론 - 통계적 추정(Statistical Estimation) (0) | 2020.03.05 |
| 중심극한정리(Central Limit Theorem) (0) | 2020.03.04 |